ClassifiedKorea
Designing an accurate search engine for classified CIA documents using Generative AI and Retrieval Augmented Generation.

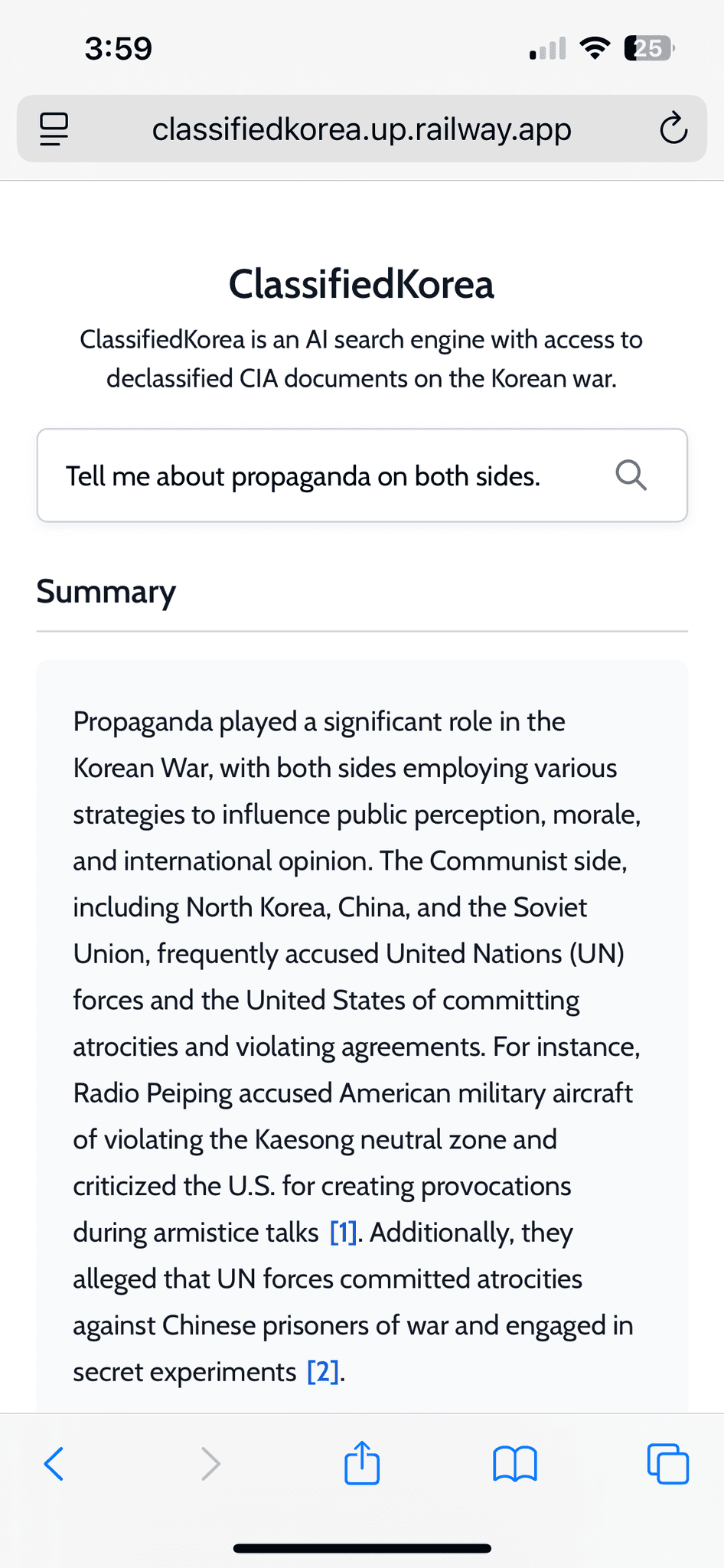

What is ClassifiedKorea?
The US government has released thousands of secret documents to the public, but no one has time to read through all of them. I wanted to design software to search these document dumps for interesting information tidbits.
ClassifiedKorea searches through a set of over 1300 released CIA documents from the Korean War, then outputs a factual summary of its findings with citations and links to the original documents.
What is ClassifiedKorea?
The US government has released thousands of secret documents to the public, but no one has time to read through all of them. I wanted to design software to search these document dumps for interesting information tidbits.
ClassifiedKorea searches through a set of over 1300 released CIA documents from the Korean War, then outputs a factual summary of its findings with citations and links to the original documents.
What is ClassifiedKorea?
The US government has released thousands of secret documents to the public, but no one has time to read through all of them. I wanted to design software to search these document dumps for interesting information tidbits.
ClassifiedKorea searches through a set of over 1300 released CIA documents from the Korean War, then outputs a factual summary of its findings with citations and links to the original documents.
What is ClassifiedKorea?
The US government has released thousands of secret documents to the public, but no one has time to read through all of them. I wanted to design software to search these document dumps for interesting information tidbits.
ClassifiedKorea searches through a set of over 1300 released CIA documents from the Korean War, then outputs a factual summary of its findings with citations and links to the original documents.
User Experience in AI?
One of the exciting things about developing with AI, in my opinion, is how it blurs the line between UX design and software development. Throughout the process, what I was really designing was an experience for historical researchers. Every decision I made was about solving user problems.
When formatting documents, I had to design for two different "users" - the LLM needed sufficient information to draw connections between documents, while the vector database required optimized input to perform effective searches.
For the output's design, my user was an academic researcher needing high quality, accurate information. I created a system of parallel agents to summarize documents (with respect to the prompt) before feeding them into a final summary generator, not just because of context window limitations, but to ensure outputs remained hyper-focused while preserving critical details that might otherwise be lost in a single-pass summarization. This approach preserved the nuanced information researchers require while delivering concise results.
For the interface, I made the deliberate choice to design it as a search rather than a chat, because chats, while standard in AI, imply persistent conversation history. A critical design decision was showing only the sources that were actually cited as footnotes, rather than displaying all documents retrieved by the vector search. This choice was actually solving a core user problem: researchers need to see genuinely relevant documents, not just algorithmically similar ones. his focus on building trust and transparency reflects how AI development decisions are fundamentally UX decisions.
User Experience in AI?
One of the exciting things about developing with AI, in my opinion, is how it blurs the line between UX design and software development. Throughout the process, what I was really designing was an experience for historical researchers. Every decision I made was about solving user problems.
When formatting documents, I had to design for two different "users" - the LLM needed sufficient information to draw connections between documents, while the vector database required optimized input to perform effective searches.
For the output's design, my user was an academic researcher needing high quality, accurate information. I created a system of parallel agents to summarize documents (with respect to the prompt) before feeding them into a final summary generator, not just because of context window limitations, but to ensure outputs remained hyper-focused while preserving critical details that might otherwise be lost in a single-pass summarization. This approach preserved the nuanced information researchers require while delivering concise results.
For the interface, I made the deliberate choice to design it as a search rather than a chat, because chats, while standard in AI, imply persistent conversation history. A critical design decision was showing only the sources that were actually cited as footnotes, rather than displaying all documents retrieved by the vector search. This choice was actually solving a core user problem: researchers need to see genuinely relevant documents, not just algorithmically similar ones. his focus on building trust and transparency reflects how AI development decisions are fundamentally UX decisions.
User Experience in AI?
One of the exciting things about developing with AI, in my opinion, is how it blurs the line between UX design and software development. Throughout the process, what I was really designing was an experience for historical researchers. Every decision I made was about solving user problems.
When formatting documents, I had to design for two different "users" - the LLM needed sufficient information to draw connections between documents, while the vector database required optimized input to perform effective searches.
For the output's design, my user was an academic researcher needing high quality, accurate information. I created a system of parallel agents to summarize documents (with respect to the prompt) before feeding them into a final summary generator, not just because of context window limitations, but to ensure outputs remained hyper-focused while preserving critical details that might otherwise be lost in a single-pass summarization. This approach preserved the nuanced information researchers require while delivering concise results.
For the interface, I made the deliberate choice to design it as a search rather than a chat, because chats, while standard in AI, imply persistent conversation history. A critical design decision was showing only the sources that were actually cited as footnotes, rather than displaying all documents retrieved by the vector search. This choice was actually solving a core user problem: researchers need to see genuinely relevant documents, not just algorithmically similar ones. his focus on building trust and transparency reflects how AI development decisions are fundamentally UX decisions.
User Experience in AI?
One of the exciting things about developing with AI, in my opinion, is how it blurs the line between UX design and software development. Throughout the process, what I was really designing was an experience for historical researchers. Every decision I made was about solving user problems.
When formatting documents, I had to design for two different "users" - the LLM needed sufficient information to draw connections between documents, while the vector database required optimized input to perform effective searches.
For the output's design, my user was an academic researcher needing high quality, accurate information. I created a system of parallel agents to summarize documents (with respect to the prompt) before feeding them into a final summary generator, not just because of context window limitations, but to ensure outputs remained hyper-focused while preserving critical details that might otherwise be lost in a single-pass summarization. This approach preserved the nuanced information researchers require while delivering concise results.
For the interface, I made the deliberate choice to design it as a search rather than a chat, because chats, while standard in AI, imply persistent conversation history. A critical design decision was showing only the sources that were actually cited as footnotes, rather than displaying all documents retrieved by the vector search. This choice was actually solving a core user problem: researchers need to see genuinely relevant documents, not just algorithmically similar ones. his focus on building trust and transparency reflects how AI development decisions are fundamentally UX decisions.
Design Process
Here's the nitty gritty of the step by step design process, the choices I made along the way, and why.
Design Process
Here's the nitty gritty of the step by step design process, the choices I made along the way, and why.
Design Process
Here's the nitty gritty of the step by step design process, the choices I made along the way, and why.
Design Process
Here's the nitty gritty of the step by step design process, the choices I made along the way, and why.
Converting PDFs to Text
My first task was converting 1300+ PDFs of varying readability to text, accurately. I tested a couple of Optical Character Recognition (OCR) options, and ultimately landed with Google's Gemini-powered OCR. Google gave me $300 of free compute for making an account, so the choice was easy - not that the quality of the output wasn't great too.
Converting PDFs to Text
My first task was converting 1300+ PDFs of varying readability to text, accurately. I tested a couple of Optical Character Recognition (OCR) options, and ultimately landed with Google's Gemini-powered OCR. Google gave me $300 of free compute for making an account, so the choice was easy - not that the quality of the output wasn't great too.
Converting PDFs to Text
My first task was converting 1300+ PDFs of varying readability to text, accurately. I tested a couple of Optical Character Recognition (OCR) options, and ultimately landed with Google's Gemini-powered OCR. Google gave me $300 of free compute for making an account, so the choice was easy - not that the quality of the output wasn't great too.
Converting PDFs to Text
My first task was converting 1300+ PDFs of varying readability to text, accurately. I tested a couple of Optical Character Recognition (OCR) options, and ultimately landed with Google's Gemini-powered OCR. Google gave me $300 of free compute for making an account, so the choice was easy - not that the quality of the output wasn't great too.
Cleaning the Text
Because of factors like typewriter keys with insufficient ink, classified stamps, and redactions, the text needed cleaning. I saved important metadata with Python then had Gemini clean up spelling mistakes and spacing errors.
Cleaning the Text
Because of factors like typewriter keys with insufficient ink, classified stamps, and redactions, the text needed cleaning. I saved important metadata with Python then had Gemini clean up spelling mistakes and spacing errors.
Cleaning the Text
Because of factors like typewriter keys with insufficient ink, classified stamps, and redactions, the text needed cleaning. I saved important metadata with Python then had Gemini clean up spelling mistakes and spacing errors.
Cleaning the Text
Because of factors like typewriter keys with insufficient ink, classified stamps, and redactions, the text needed cleaning. I saved important metadata with Python then had Gemini clean up spelling mistakes and spacing errors.
Formatting JSON Documents
When creating a vector database for RAG, you need both the content (which is used to match search results to queries) and metadata (which is given to the AI model to help contextualize the content).
AI models can only handle so much information at once, so document chunking was necessary. I made my chunks as long as possible, because I wanted to give my LLM a lot to work with. CIA documents often start with a list of descriptors that contextualize the entire document. I didn't want chunks in the middle of the document to lose this context, so I extracted it via traditional programming and applied it to each chunk's content.
I also included links and date of publication in the JSON metadata. These data fields were never touched by an LLM and were only handled via traditional programming, ensuring that no hallucination would impact citation validity at this stage.
Formatting JSON Documents
When creating a vector database for RAG, you need both the content (which is used to match search results to queries) and metadata (which is given to the AI model to help contextualize the content).
AI models can only handle so much information at once, so document chunking was necessary. I made my chunks as long as possible, because I wanted to give my LLM a lot to work with. CIA documents often start with a list of descriptors that contextualize the entire document. I didn't want chunks in the middle of the document to lose this context, so I extracted it via traditional programming and applied it to each chunk's content.
I also included links and date of publication in the JSON metadata. These data fields were never touched by an LLM and were only handled via traditional programming, ensuring that no hallucination would impact citation validity at this stage.
Formatting JSON Documents
When creating a vector database for RAG, you need both the content (which is used to match search results to queries) and metadata (which is given to the AI model to help contextualize the content).
AI models can only handle so much information at once, so document chunking was necessary. I made my chunks as long as possible, because I wanted to give my LLM a lot to work with. CIA documents often start with a list of descriptors that contextualize the entire document. I didn't want chunks in the middle of the document to lose this context, so I extracted it via traditional programming and applied it to each chunk's content.
I also included links and date of publication in the JSON metadata. These data fields were never touched by an LLM and were only handled via traditional programming, ensuring that no hallucination would impact citation validity at this stage.
Formatting JSON Documents
When creating a vector database for RAG, you need both the content (which is used to match search results to queries) and metadata (which is given to the AI model to help contextualize the content).
AI models can only handle so much information at once, so document chunking was necessary. I made my chunks as long as possible, because I wanted to give my LLM a lot to work with. CIA documents often start with a list of descriptors that contextualize the entire document. I didn't want chunks in the middle of the document to lose this context, so I extracted it via traditional programming and applied it to each chunk's content.
I also included links and date of publication in the JSON metadata. These data fields were never touched by an LLM and were only handled via traditional programming, ensuring that no hallucination would impact citation validity at this stage.
Creating a Vector Database
A vector database stores document embeddings as numerical vectors, allowing researchers to search for information based on meaning rather than just keywords. For my project, it formed the backbone of the retrieval system, enabling the AI to quickly find the most contextually relevant historical documents when researchers entered queries.
I used Pinecone to build and host my vector database. They are very kind and provide a lot of free storage and querying.
Creating a Vector Database
A vector database stores document embeddings as numerical vectors, allowing researchers to search for information based on meaning rather than just keywords. For my project, it formed the backbone of the retrieval system, enabling the AI to quickly find the most contextually relevant historical documents when researchers entered queries.
I used Pinecone to build and host my vector database. They are very kind and provide a lot of free storage and querying.
Creating a Vector Database
A vector database stores document embeddings as numerical vectors, allowing researchers to search for information based on meaning rather than just keywords. For my project, it formed the backbone of the retrieval system, enabling the AI to quickly find the most contextually relevant historical documents when researchers entered queries.
I used Pinecone to build and host my vector database. They are very kind and provide a lot of free storage and querying.
Creating a Vector Database
A vector database stores document embeddings as numerical vectors, allowing researchers to search for information based on meaning rather than just keywords. For my project, it formed the backbone of the retrieval system, enabling the AI to quickly find the most contextually relevant historical documents when researchers entered queries.
I used Pinecone to build and host my vector database. They are very kind and provide a lot of free storage and querying.
Designing RAG Architecture
Retrieval Augmented Generation at its core is actually really simple; it's just giving an AI relevant sources to read before answering.
My RAG added one intermediate step: I gave relevant sources to multiple agents, which summarized documents with respect to the question asked. Then, those summaries were fed to a final ChatGPT instance to generate a final output.
This was more expensive, but it generated helpful summaries of each document for the footnote section, and separating the summary and synthesis steps made all outputs better.
Designing RAG Architecture
Retrieval Augmented Generation at its core is actually really simple; it's just giving an AI relevant sources to read before answering.
My RAG added one intermediate step: I gave relevant sources to multiple agents, which summarized documents with respect to the question asked. Then, those summaries were fed to a final ChatGPT instance to generate a final output.
This was more expensive, but it generated helpful summaries of each document for the footnote section, and separating the summary and synthesis steps made all outputs better.
Designing RAG Architecture
Retrieval Augmented Generation at its core is actually really simple; it's just giving an AI relevant sources to read before answering.
My RAG added one intermediate step: I gave relevant sources to multiple agents, which summarized documents with respect to the question asked. Then, those summaries were fed to a final ChatGPT instance to generate a final output.
This was more expensive, but it generated helpful summaries of each document for the footnote section, and separating the summary and synthesis steps made all outputs better.
Designing RAG Architecture
Retrieval Augmented Generation at its core is actually really simple; it's just giving an AI relevant sources to read before answering.
My RAG added one intermediate step: I gave relevant sources to multiple agents, which summarized documents with respect to the question asked. Then, those summaries were fed to a final ChatGPT instance to generate a final output.
This was more expensive, but it generated helpful summaries of each document for the footnote section, and separating the summary and synthesis steps made all outputs better.
Designing Front End Interface
Finally, I designed a front end that took in people's questions and displayed ChatGPT's answers. I designed the front end like a search engine rather than a conversation, because my model didn't have memory between queries. I also formatted citations nicely and provided the intermediate summaries for the reader's convenience. Typography was a consideration – to preserve readability, I kept text line length short, even on big screens.
If you've gotten this far without trying it - check it out!
Designing Front End Interface
Finally, I designed a front end that took in people's questions and displayed ChatGPT's answers. I designed the front end like a search engine rather than a conversation, because my model didn't have memory between queries. I also formatted citations nicely and provided the intermediate summaries for the reader's convenience. Typography was a consideration – to preserve readability, I kept text line length short, even on big screens.
If you've gotten this far without trying it - check it out!
Designing Front End Interface
Finally, I designed a front end that took in people's questions and displayed ChatGPT's answers. I designed the front end like a search engine rather than a conversation, because my model didn't have memory between queries. I also formatted citations nicely and provided the intermediate summaries for the reader's convenience. Typography was a consideration – to preserve readability, I kept text line length short, even on big screens.
If you've gotten this far without trying it - check it out!
Designing Front End Interface
Finally, I designed a front end that took in people's questions and displayed ChatGPT's answers. I designed the front end like a search engine rather than a conversation, because my model didn't have memory between queries. I also formatted citations nicely and provided the intermediate summaries for the reader's convenience. Typography was a consideration – to preserve readability, I kept text line length short, even on big screens.
If you've gotten this far without trying it - check it out!
Next Steps + Limitations
There are two ways I could move forward. The first would be to double down on the Korean War topic, incorporating more document types and languages. The second would be to widen the scope to cover all released CIA documents. If you have thoughts, please reach out!
Of course, there are limitations to what I designed. I didn't build any rate limiting or user authentication, so someone could theoretically use up all of my OpenAI credits if they wanted. The API also isn't great at handling multiple queries at once (sometimes it loses document summaries) so if more people used this I would have to fix that as well.
Next Steps + Limitations
There are two ways I could move forward. The first would be to double down on the Korean War topic, incorporating more document types and languages. The second would be to widen the scope to cover all released CIA documents. If you have thoughts, please reach out!
Of course, there are limitations to what I designed. I didn't build any rate limiting or user authentication, so someone could theoretically use up all of my OpenAI credits if they wanted. The API also isn't great at handling multiple queries at once (sometimes it loses document summaries) so if more people used this I would have to fix that as well.
Next Steps + Limitations
There are two ways I could move forward. The first would be to double down on the Korean War topic, incorporating more document types and languages. The second would be to widen the scope to cover all released CIA documents. If you have thoughts, please reach out!
Of course, there are limitations to what I designed. I didn't build any rate limiting or user authentication, so someone could theoretically use up all of my OpenAI credits if they wanted. The API also isn't great at handling multiple queries at once (sometimes it loses document summaries) so if more people used this I would have to fix that as well.
Next Steps + Limitations
There are two ways I could move forward. The first would be to double down on the Korean War topic, incorporating more document types and languages. The second would be to widen the scope to cover all released CIA documents. If you have thoughts, please reach out!
Of course, there are limitations to what I designed. I didn't build any rate limiting or user authentication, so someone could theoretically use up all of my OpenAI credits if they wanted. The API also isn't great at handling multiple queries at once (sometimes it loses document summaries) so if more people used this I would have to fix that as well.